Lets get started !
You know that moment when your Socket.IO server starts choking under load? Users complain about dropped connections, messages arrive out of order, and your monitoring dashboard lights up like a Christmas tree. We’ve been there.
The problem gets worse with AI applications. A single chat message can trigger a 30-second LLM response that streams thousands of tokens. Multiply that by hundreds of concurrent users and you’ve got a scaling problem.
Here’s how we built Weam to handle it.
Why Socket.IO Hits a Wall
A single Node.js process can handle around 10,000 to 30,000 concurrent Socket.IO connections before things get ugly. That sounds like a lot until you realize what happens when you need to scale beyond one server.
Let’s say User A connects to Server 1 and User B connects to Server 2. When User A sends a message, Server 1 gets it. But Server 2 has no idea anything happened. The servers can’t talk to each other out of the box.
You could try running everything on one beefy server, but that’s asking for trouble. One process crash and everyone gets disconnected. No redundancy, no load distribution, no room to grow.

The Redis Pub/Sub Solution
Redis Pub/Sub acts as a message broker between your Socket.IO servers. When one server needs to broadcast an event, it publishes to Redis. Redis then delivers that message to all other servers. Those servers emit the event to their connected clients.
It’s like having a central post office. Each server drops messages in the mailbox and picks up messages meant for its clients.
Here’s what the setup looks like:
You need two Redis connections because the subscribe operation blocks. One client subscribes to channels and receives messages, while the other publishes messages. This separation keeps everything flowing smoothly.
How Messages Flow Across Servers
Let’s walk through what happens when a user sends a chat message in Weam:
- User A (connected to Server 1) emits an ai-query event
- Server 1 receives the event and processes it locally
- Server 1 broadcasts the AI response to the chat room
- Redis adapter publishes this broadcast to Redis
- Redis delivers the message to Server 2 and Server 3
- Those servers emit the response to any clients in that room
- User B (on Server 2) receives the AI response in real time
Sticky Sessions with Load Balancers
There’s one catch with multiple Socket.IO servers: you need sticky sessions. When a client connects, it needs to keep hitting the same server for the entire session.
Socket.IO uses HTTP long-polling as a fallback before upgrading to WebSockets. If the polling requests hit different servers, the connection breaks.
Here’s an nginx configuration that handles this:
The ip_hash directive ensures requests from the same IP address always hit the same backend server. Problem solved.
If you’re using a cloud load balancer like AWS ALB, enable sticky sessions in the target group settings. Most load balancers support this.
Handling Streaming AI Responses
AI responses don’t arrive all at once. GPT-4 or Claude sends tokens progressively, which is great for user experience but tricky for your infrastructure.
A single AI response might stream for 30 seconds and emit 50+ socket events. That’s 50+ Redis publishes per response. Multiply by 100 concurrent users and you’ve got 5,000 Redis operations in 30 seconds.
Redis handles this easily, but you need to think about message size. Streaming tokens character by character creates too much overhead. We batch tokens into chunks:
This reduces the number of Redis publishes while keeping the streaming experience smooth.
Room-Based Isolation
Weam uses Socket.IO rooms to isolate conversations. Each chat session gets its own room. Users join the room when they open a chat and leave when they close it.
Rooms work seamlessly with Redis adapter. When Server 1 emits to a room, Redis ensures all servers deliver the message to clients in that room.
Monitoring What Matters
You can’t scale what you don’t measure. We track these metrics:
Connection Count Per Server:
Message Latency:
Redis Pub/Sub Stats:
redis-cli INFO stats | grep instantaneous
Watch for instantaneous_ops_per_sec. If it starts climbing above 50,000, you might need Redis clustering.
When Things Go Wrong
Problem: Messages arrive out of order
This happens when multiple servers process events concurrently. We add sequence numbers to maintain order:
let sequenceNumber = 0;
io.to(roomId).emit('ai-response-stream', {
chunk: data,
sequence: ++sequenceNumber,
done: false
});The client sorts by sequence number before rendering.
Problem: Connections drop during deployments
Use graceful shutdown to drain existing connections:
Deploy new servers before shutting down old ones. This prevents connection loss.
Problem: Redis becomes a bottleneck
If a single Redis instance can’t keep up, switch to Redis Cluster. The Socket.IO Redis adapter supports it:
Testing at Scale
Don’t wait until production to discover your limits. Load test your Socket.IO setup early.
We use Artillery for this:
Run this against multiple servers and watch how they handle the load. Look for memory leaks, connection drops, and message delays.
CPU Utilization Across Servers
Node.js is single-threaded, so one process maxes out one CPU core. If you’ve got a server with 8 cores, run 8 Socket.IO processes.
Use PM2 to manage this:
pm2 start server.js -i 8PM2 automatically load balances connections across processes. Each process connects to Redis, so they all stay in sync.
The Cost of Scaling
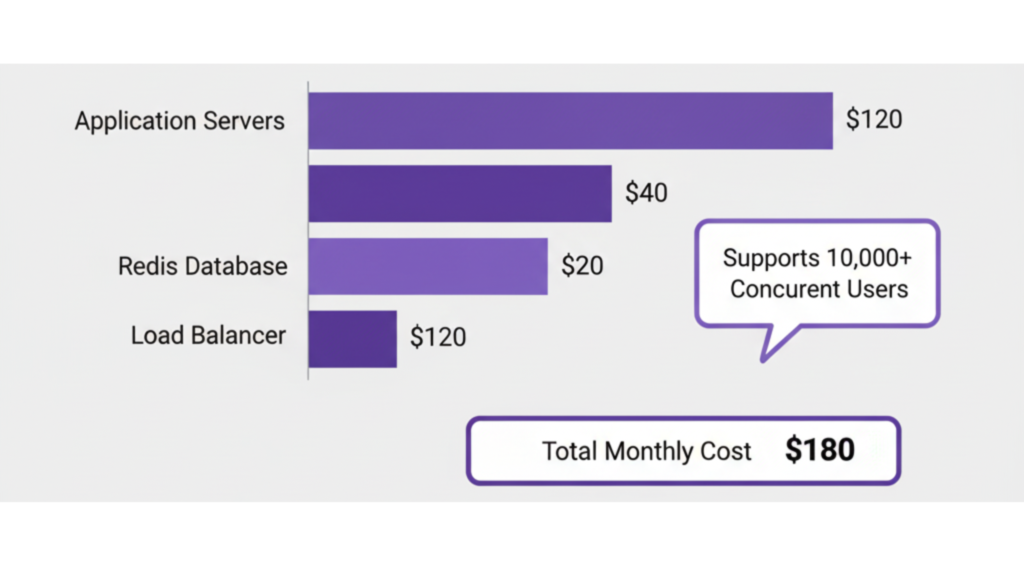
Running multiple servers and Redis adds infrastructure cost. Here’s what we spend monthly for 10,000 concurrent users:
- 3x Application Servers (4 vCPU, 8GB RAM each): $120
- 1x Redis Instance (2 vCPU, 4GB RAM): $40
- Load Balancer: $20
Total: $180/month for infrastructure that handles peak load comfortably.
Compare that to the cost of downtime or lost users due to performance issues. The investment pays off quickly.
Start Simple, Scale When Needed
You don’t need Redis Pub/Sub on day one. Start with a single Socket.IO server and monitor your connection count. When you consistently hit 5,000+ concurrent connections, that’s your signal to scale horizontally.
The transition isn’t painful. Add Redis, update your Socket.IO initialization, configure sticky sessions, and deploy a second server. Your application code stays the same.
We went from one server handling 2,000 connections to three servers handling 15,000 connections in an afternoon. The Redis adapter made it painless.
Just remember: scaling isn’t about handling traffic you might get someday. It’s about building a system that grows with you when you actually need it.



